Context Switching
Context switching is the bane of productivity. For those of you not familiar with the term: context switching is when one is forced to switch from one topic or work item to the next. This is also known as multi-tasking. Sadly, too many people believe they are excellent multi-taskers. This is nonsense. Nobody is an excellent multi-tasker.
The brain is single threaded. We are not processors that can be running two tasks in parallel. We don’t have the internal CPU for such a job. Every time we switch tasks, we have to rebuild our mental architecture. We have to tear down the thought processes for our current task and replace them with the thought processes for the new task. This takes time when we are working in a vacuum. But when’s the last time you worked in a vacuum? Think about how much more time this takes when we are getting interrupted on a regular basis.
This is the famous chart that Gerry Weinberg put together to illustrate the waste caused by context switching.
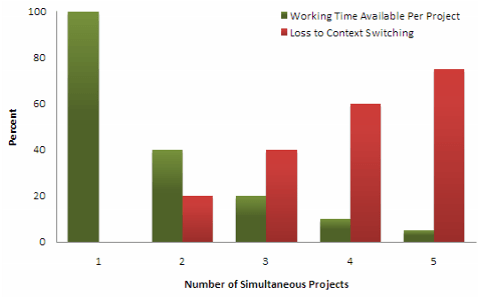
If the numbers aren’t working for you in the first chart, that is because several assumptions are being made. The chart below explains those assumptions in a little more detail.

If you don’t find these graphs shocking, you’re not reading them right. If you are working on two projects at one time, then you are losing a full 20% of your productivity. If you are working on 5? 75% of your productivity goes straight in the shitter. To say that another way, when you are working five projects, each project gets 1/20th of your time. Rebuilding your mental architecture each time gets 3/4ths of your time.
That doesn’t apply to me, I’m a great multi-tasker
Oh yeah? If you are such a good multi-tasker do these two simple tasks for me: recite the lyrics of your favorite song and calculate the square root of 2,116. The hitch? You have to do these two tasks at the same time. Start the lyrics now and do not pause. Before you finish those lyrics, come up with the answer to the math problem.
In my personal experiments, one of two things happen here. The person gives up OR they come up with the right answer to the math problem but keep losing their place in the song. Humans are NOT capable of multi-tasking. Unless you are a cyborg or have figured out how to split your brain, please stop claiming that you are a good multi-tasker. My crappy personal experimentation aside, the science is in. You can start here for more info: http://www.npr.org/templates/story/story.php?storyId=95256794.
There is always some wise-ass at this point that asks the question: if that is true how can I drive and hold a conversation? OR, how can I chew gum and walk at the same time. The answer: habits don’t count. The things that you have done so many times where your lizard brain takes over and the action gets moved to auto pilot don’t rely on higher level thought. We are only talking about those tasks that take higher level thought. Which, hopefully, is most of the tasks you do every day at work.
Interesting sidebar edit: It took me an hour and a half to write 80% of this column. I received a phone call when I was almost done writing that I had to take. It took me another hour and a half to write the final 20%. Context switching in action.
So what do we do about this loss of productivity?
One of my old bosses had a great philosophy: you want to move faster? Do less at one time. This is another way of stating the old maxim that less is more.
Let’s get specific and address one of two primary issues where context switching is a huge killer: software development. We’ll cover the other productivity killing issue, meetings, in the next post.
Cut your WIP (work in progress) ASAP
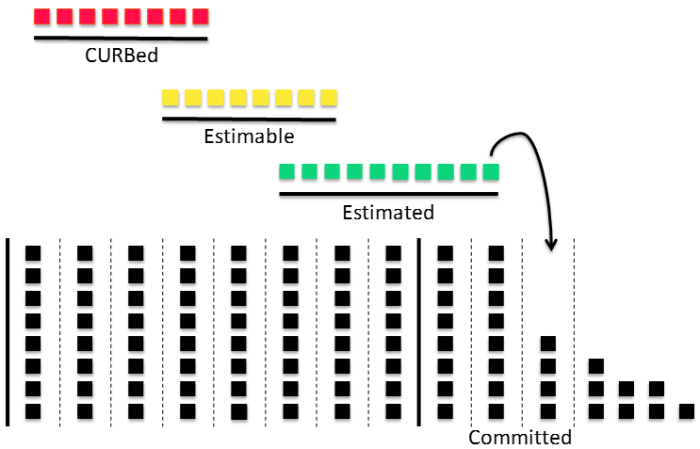
This is where the less is more rubber hits the road. When it comes to agile, one of the questions we need to be asking ourselves all the time is how much we can cut our work in progress. This questioning is where Kanban can be incredibly effective. Kanban translates to ‘visual signal’ and was pioneered on the floors of Toyota plants back in the fifties. Most people will use Kanban to give the team and folks outside of the team insight on the progress of work. Boards like the one below can be seen in almost every agile shop out there:
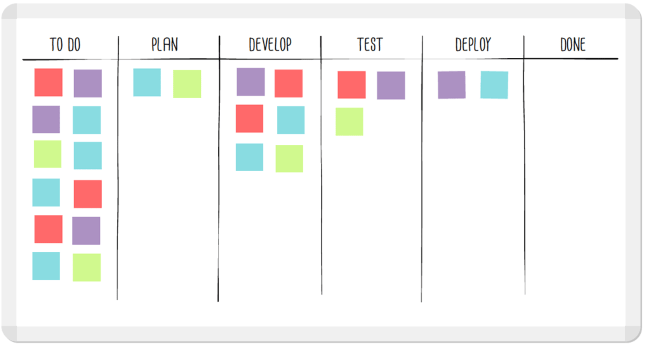
Unfortunately, for most teams, that’s where the utilization of Kanban ends. This is a shame. If you end with just the visual representation of the work moving from stage to stage you are missing out on the critical improvements that Kanban can offer you and your team. As you dive deeper you realize that much of the benefit of Kanban comes from identifying and eliminating bottlenecks.
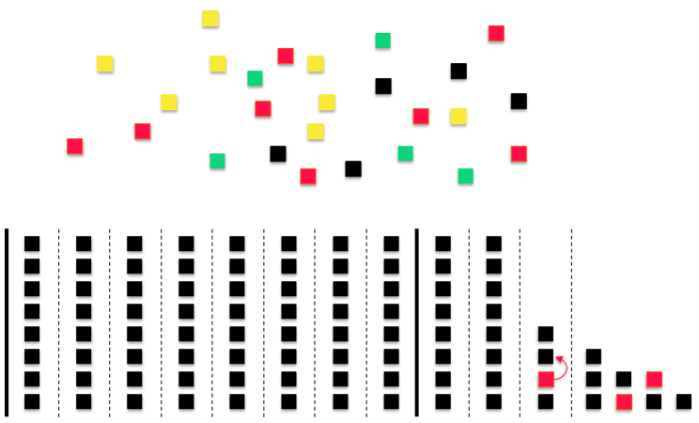
One of the ways to tell if you have bottlenecks is to identify where most of your cards are backing up on your Kanban board. If most of your cards are in your backlog (to do) or sitting in Done, this isn’t much of a problem for your team. If however, most of your cards end up sitting in develop or test for most of the sprint right up until the last day: you’ve got WIP problems.
WIP problems typically fall into two categories: context switching and process problems. These categories have a ton of overlap, so we’ll talk about both together.
Set fixed limits for WIP
In a previous life, one of the teams I worked with had six devs, three QA and a product owner. Our rule for this group was the team could only have six WIP cards that were between the backlog and the done swim lanes.
The reaction to this early on was unexpected. The developers complained that they would be sitting on their hands a lot waiting. Granted, there was some hand sitting but not nearly as much as you would think. Instead, the team gelled better than ever before. A lot of agile teams pay lip service to the idea that no matter the task, the whole team pitches in to move product through the pipeline. So dev will help with QA, QA will help with requirements definition, etc. The sad reality is that these teams almost always get siloed. Developers just work on dev and QA just works on quality.
What happened with our team after instituting very strict WIP limits is that the devs got a lot more involved with the QA process and helped test other developer’s stories. In doing that testing, they gained a much better understanding of how QA was writing test cases. Most QA folks can’t code so QA didn’t implement any stories but the QA team got much more involved in the definition of these stories. Our devs also learned how valuable a good unit test is.
In the end, the numbers told the final story. That team went from an average push rate (work items being pushed at the end of a sprint) of 17% to under 5%. And their overall velocity increased by 10%. What we found was that keeping the whole team focused on a small number of items at one time caused us to move a lot faster. Less is more when you limit context switching.
You will need to play around with what your WIP limits are but err on the side of less work items at first. Even though it may feel like some people are sitting around waiting to work, people generally like to work. Chances are, you will find them helping out with other jobs and understanding the process as a whole a lot better. You will also quickly identify your bottlenecks. For us, the bottleneck was QA. Having developers finish more stories was only backing up the QA machine in the production line. Having dev help out with QA made everyone faster.
Segregate the issues coming in from the field
Another issue that can completely destroy your team’s productivity is adding work items to the sprint after the sprint has started. This is agile 101. Most of you know this and know that most product owners would never dare to add a new work item mid sprint. But what happens when a defect comes in from the field? This issue turns out to be bad enough that the customer is genuinely pissed off and now you have your CEO breathing down your neck.
The most effective way I’ve found to deal with this issue is to build a dev support team. We had a rotating dev support team that was made up of one developer with another on back up. The person on the dev support team was only on that team for two sprints at a time. Then they would move to the backup position. When they were the primary support dev, their only job was to handle issues coming in from the field. When there were no issues coming in from the field, they would fix defects. They were never assigned story work.
This is another great anti-silo approach. This forces all of your developers to become familiar with the entire codebase. It also shows you as a leader, how your different devs react to stress.
What if I’m on a custom software team?
If you’re building custom software for clients, context switching comes with the territory. It can be managed but not eliminated. The most effective custom or outsource teams that I have worked with manage this in a couple of ways. First, they budget for the context switching costs. Most of these teams have been doing this long enough that they understand the impact of context switching WAY better than product development teams so they incorporate it into their estimates. They also mitigate some of the risk by trying to keep their resources on one project and only one project as long as they can. When that is not a possibility, the best outsource teams that I have worked with try to limit their resources to working on only one project per day. It’s easier to rebuild that mental architecture if you only have to do it once per day.
Conclusion
None of us can multi-task effectively which is why context switching is such a killer. Acknowledging that multi-tasking is the problem is the first step in the healing process. The more you can eliminate context switching from your life and the lives of your team, the more productive you will be. This is part one of the context switching topic wherein we covered the mechanics of context switching in the agile product cycle. In the next post we will cover the other big context switching time thief, meetings.