If you are using scrum successfully, this is probably obvious to you. I’ve been doing a fair amount of consulting lately and I’ve worked with a lot of teams where blowing up sprints is common practice. Let me define what I mean by blowing up a sprint.
A sprint blow up is when you have a fixed length sprint, we’ll call it two weeks, and midway into the sprint you decide to change scope. This could be due to a defect coming in from the field. This could be because the CEO wants to work on something different. It could be because the product owner changed their mind about a feature.
Regardless of the reason for the blow up, it is typically done with little forethought. It’s almost never done with maliciousness. The primary reason for a sprint blow up is ignorance. The person blowing up the sprint will typically ask, why can’t I just replace this 3 point story with that 3 point story? Pretty reasonable question right?
As software engineers, it is up to us to educate why it is such a bad idea to blow up a sprint. There are two overarching reasons why sprint blow ups are so disruptive. The first reason is cultural, the other(s) is technical.
When business leaders decide to use agile, they are often told that one of the benefits is that their developers will commit to hitting each sprint. For business leaders that have any memory of the old waterfall days where being six months over estimate was more common than inappropriate yoga pants at a Walmart, this sounded like a pretty good deal. The problem was, no one told these leaders the full story.
A sprint is a contract

The folks building and testing product are committing to hitting a sprint. In return, the rest of the company is committing to not changing the contents of that sprint for the duration of that sprint. That is the contract. I can tell almost immediately when I walk in to a dev shop where blowing up sprints is commonplace. The developers and QA all have a defeated, hang dog look about them and the rest of the company has very little respect for them. The rest of the company ends up blaming the development team for not hitting their commitments without the slightest understanding that they are the ones in breach of contract.
You know what happens to good developers in this type of toxic culture? Yep, they leave. Nobody wants to work in a culture where everyone is blaming them for failure.
Before we get to the technical challenges around sprint blow ups let’s first answer the question – why can’t I just swap out this 3 point story with that 3 point story? The answer to that is estimation is not an exact science. Story points estimates are no more accurate than t-shirt sizes. We’ve all experienced putting on an XL t-shirt that wears like body paint, while putting on another XL that fits like a moo moo. I have anyway. When the team is doing their estimates, everybody in the room knows which story is a heavy 5 and which story is a light 3. When they commit to the sprint, they’re all doing the inner calculus that says ‘I may fall a little behind on that heavy 5 but I’m sure I can pick it up on that light 3.’
When you blow up the sprint, that inner calculus disappears. You have invalidated the development team’s commitment. Once the sprint is violated, those commitments can no longer be honored.
What if we have no choice?
The most common complaint I get when passing on this advice is – well what about issues coming in from the field? We can’t just leave our customers high and dry. I agree, you can’t leave your customers hanging especially if you’re dealing with high priority defects.
The best answer to this is to have a team that is dedicated to customer issues that is outside of the sprint development cycle. This is typically only one dev and one QA person and that QA person can even be part time. When that dev is not fielding high priority issues from the field, they are fixing defects or refactoring tech debt. This should be a rotating position. When doing two week sprints, dev support should only be for two sprints at a time. This is a great way to spread the burden, so you don’t get one developer who ends up being the go to guy for all defects coming in. It is also a great way to make sure everyone is familiar with the majority of the code base. There’s no better way to train new developers than to throw them into that hot seat. Sure, they’ll get help from other members of the team, but when it’s your ass on the line you will learn that code quickly.
What happens if your team is not big enough to field even one developer to handle these issues coming in from the field? Please don’t try to half ass this. I’ve worked with a couple of teams where they said – “we just budget x% of the sprint to manage defects coming in.” This will never work. You can’t budget for chaos. When defects come in, they might take up 5% of the sprint, or more commonly, they end up taking more like 50% of the sprint. Not to mention that defects are damn near impossible to estimate in the first place. If the devs knew what the problem was, they wouldn’t have written the defect into the code in the first place. Either way, the defect kills that inner calculus and the sprint is destroyed.
The short answer is if your team is too small to handle field issues outside of the sprint, you shouldn’t be using scrum. Scrum only works when the contract is upheld. I’d recommend Kanban instead.
What are the engineering reasons you shouldn’t blow up a sprint?
I’ll list several more reasons here if you still need to articulate why blowing up a sprint is a bad idea. This list could easily be expanded and I recommend you to do so. It’s cathartic. When swapping out stories or throwing in defects to blow up a sprint, outside of the estimation issue, you are also not accounting for:
- The work already started (half of story B is left unfinished)
- The de-risking required for the new stories (which is normally just skipped and you wing it)
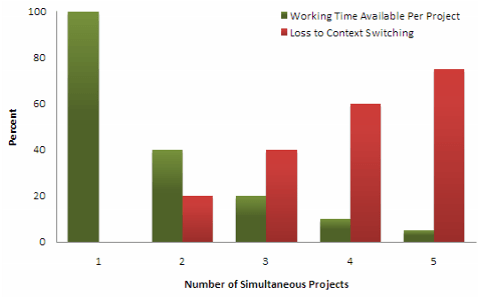
- Context switching
- The environmental set-ups (things like supporting data sets, integration points, etc.) required to build certain stories
- The branching required to quarantine started work
- The branching required to start new work
- New dependencies introduced by the new work
- New integration testing and merging required by the new work
- Changes in release strategies if necessary
You want to bring dignity back to a development environment and culture? Stop blowing up those sprints!