Requirements and the agile SDLC
Everyone is familiar with the expression, ‘garbage in equals garbage out’ by now. This simple statement neatly articulates the necessity for quality software requirements. Before you roll your eyes about yet another post on how to create software requirements, know that we are going to take a slightly different approach.
If you’re building a simple web or mobile app a basic knowledge of any of the agile philosophies is all you need. They will have you putting together solid user stories to get you to a reliable end result. What happens when you are dealing with far more complexity, like enterprise software? How does this change the agile paradigms, if at all?
Let’s look at this through the lens of an enterprise R&D team. Some of the questions that R&D regularly deals with: how do you build software requirements when you don’t even know if what you want to build is technically possible? Or, how do you reliably build requirements for a new component to an enterprise product when you don’t know what the integration between the new component and the existing components looks like? When does product management even get involved with these types of early stage modeling?
The root of the issue is managing unknowns. More specifically, big unknowns. These unknowns are too large for a single research spike. For those of you not familiar, a research spike is a timeboxed user story with the goal of answering a question or gathering information rather than shipping product. Typically, these are created when a user story is generated that cannot be well estimated until the dev team does some work to try to resolve a design issue or a technical question.
Another problem that arises fairly often when unknowns are present is research spike breeding. One research spike is created, the answers are not sufficient, so that research spike creates three more. Each of those create more and very quickly your sprint has been taken over by these cunicular little beasts.
One of the keys to a successful agile sprint is small stories that can be completed in one sprint. Where a ton of agile teams, especially new ones, fall on their faces is adding stories that can’t be completed in a single sprint. This causes the dreaded story push at the end of the sprint. Or, even worse, extending the sprint. More often than not, these stories are pushed again and again. Sound familiar?
So what can you do about it? The best way to get over this hurdle is through de-risking.
One of the best descriptions of scrum at an enterprise level that I’ve seen came from one of my mentors, Dr. Tom Ngo. He created the diagram below. Each block represents a potential story or epic story. The black vertical lines of blocks at the bottom represent sprints or iterations of these stories. This diagram represents the progression of risky stories to stories that can actually be completed in one sprint.
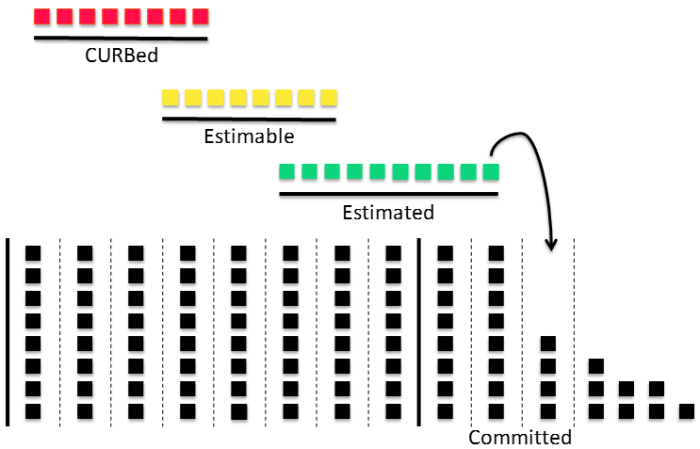
CURBed is an acronym that we made up that stands for Complex, has Unknowns, Research required or too Big. These red blocks are raw ideas and are typically high risk. It is up to your product and architecture teams to eliminate this risk and make these estimable by your dev and QA teams. We’ll get into some guidelines of how you do that in a minute. Once the team estimates these stories, only then can they be committed to a sprint.
Compare this to what a lot of teams do in this situation. They don’t go through a thorough de-risking process. Instead, they come up with a lot of cool ideas, get a ballpark estimate on each idea from one of their developers, then add it to a sprint. That looks a little like this:
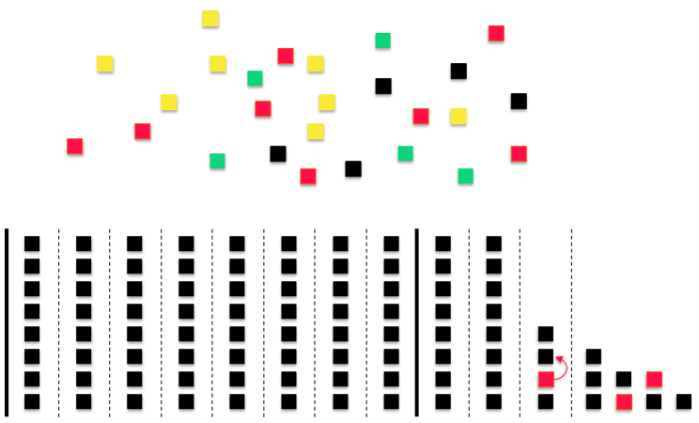
The result is typically chaos. You end up with a lot of pissed off stakeholders wondering why you can’t seem to ever hit a single commitment. Stories end up on sprints with dependencies, research spikes are multiplying like rabbits and your PO is in a constant panic. Not a fun way to work.
De-risking in the agile SDLC
Enter de-risking stage left. This is what the path of de-risking looks like:
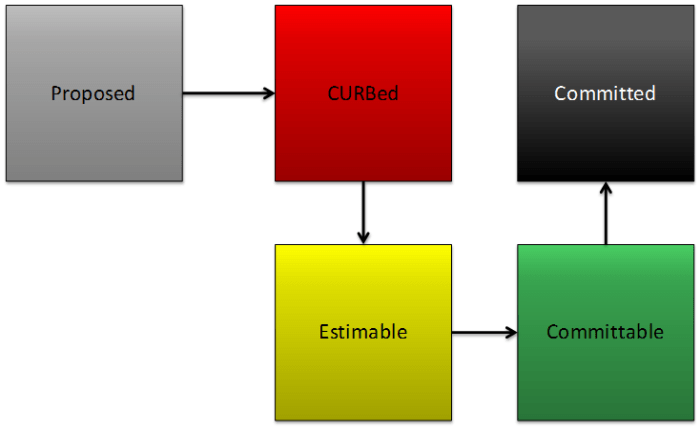
Proposed ideas enter in raw form. The product team and the architecture team prioritize and start de-risking. The hardest step is going from CURBed to estimable. Once you get to estimable, dev and QA can do some estimate poker and quickly get you to an estimated or committable state fairly quickly. The queue of committable stories becomes your product backlog. Then it’s up to your PO to decide when these items get thrown on the sprint.
9 critical steps of agile design
Every team is going to have to deal with getting from high risk, or CURBed stories, to something that is estimable in their own way. Building a plan and sticking to it is the most important step you can make to start reigning in the chaos. This is a methodology that worked for us and that has also worked for other teams with whom I’ve consulted. This is what I call the 9 Critical Steps of Design or how to get from CURBed to estimable.
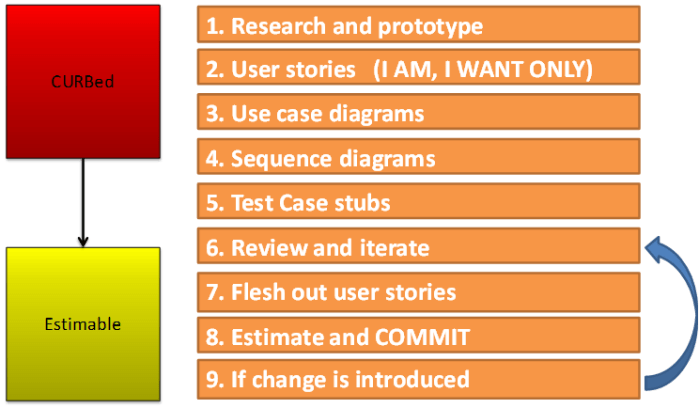
It starts with figuring out the science of the problem. If the team has never used an element of the tech stack or proposed design pattern, you have to prototype the hell out of it. This includes bringing in outside expertise if necessary. This is just for tough problems that the team has never worked on before. If it’s just a coding exercise and you know the science, you can skip the prototype phase. Don’t get complacent though because these prototypes are critical to future success. If you have the time, always prototype.
Once the science is worked out, you can start on the high level stories. We are talking very high level: ‘I am an administrator and I want to be able to log in to another user’s account’ as an example. Don’t get more detailed yet. Steps three and four are critical. This is where the team gets aligned. I’ll do another post on use case diagrams and sequence diagrams. The goal of these diagrams is to eliminate confusion but also to set your devs up for success. Every dev should have the information to implement any of these stories once these diagrams are built.
Once those diagrams are in place, the QA team can start building out test case stubs. QA is a huge weapon in the design process. Developers and architects think about how to build the product. QA thinks about how to break it. If you are not using their destructive nature in the design and de-risking process, you’re doing it wrong.
After a review, the product team can then start filling out the details of things like acceptance criteria. Step 8, estimate and commit, really happens after the estimable phase and is what takes the team to committable. Use whatever tools are in your arsenal to do the estimate, then add those stories to your backlog.
The feedback loop is important here too. Many teams that I have worked with started well until change was introduced. This change typically came in as a customer request or customer feedback. The teams then fell back into their old patterns of trying to throw those items directly on the sprint once again without design. The end result: chaos.
The overhead of going through a process like this looks high until you look at the alternative. Nobody wants chaos in their organization. Yes, agile’s primary goal is to adapt to change. This does not mean that you have to sacrifice all predictability. You may not know what the product looks like six sprints down the road but you should know what it looks like at the end of the current sprint. Without de-risking, this is almost never true.
Are you ready to end the chaos in your product delivery org? Start de-risking.
